Filebeat的配置文件是/etc/filebeat/filebeat.yml,遵循YAML语法。具体可以配置如下几个项目:
Filebeat
Output
Shipper
Logging(可选)
Run Options(可选)
这个Blog主要讲解Filebeat的配置部分,其他部分后续会有新的Blog介绍。
Filebeat的部分主要定义prospector的列表,定义监控哪里的日志文件,关于如何定义的详细信息可以参考filebeat.yml中的注释,下面主要介绍一些需要注意的地方。
filebeat.prospectors:
- input_type: log
paths:
- /log/channelserver.log
#- /home/wang/data/filebeat-5.0.2-linux-x86_64/test.log
encoding: gbk
symlinks: true
include_lines: ['\[.*?统计\]','\[.*?结算\]']
document_type: channelserver
fields_under_root: true
fields:
host: 192.168.10.155
processors:
- drop_fields:
#fields: ["beat.hostname", "beat.name", "beat.version", "input_type", "beat"]
fields: ["input_type", "beat", "offset", "source"]
output.redis:
enabled: true
hosts: ["192.168.10.188"]
port: 6379
datatype: list
key: "filebeat"
db: 0
output.file:
enabled: true
path: "/tmp/filebeat"
output.console:
enabled: false
paths:指定要监控的日志,目前按照Go语言的glob函数处理。没有对配置目录做递归处理,比如配置的如果是:
/var/log/* /*.log
则只会去/var/log目录的所有子目录中寻找以”.log”结尾的文件,而不会寻找/var/log目录下以”.log”结尾的文件。
encoding:指定被监控的文件的编码类型,使用plain和utf-8都是可以处理中文日志的。
input_type:指定文件的输入类型log(默认)或者stdin。
exclude_lines:在输入中排除符合正则表达式列表的那些行。
include_lines:包含输入中符合正则表达式列表的那些行(默认包含所有行),include_lines执行完毕之后会执行exclude_lines。
exclude_files:忽略掉符合正则表达式列表的文件(默认为每一个符合paths定义的文件都创建一个harvester)。
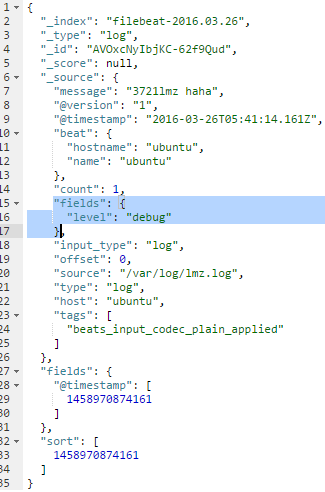
fields:向输出的每一条日志添加额外的信息,比如“level:debug”,方便后续对日志进行分组统计。默认情况下,会在输出信息的fields子目录下以指定的新增fields建立子目录,例如fields.level。
fields:
level: debug
则在Kibana看到的内容如下:
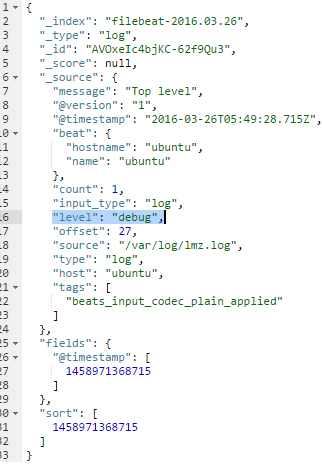
fields_under_root:如果该选项设置为true,则新增fields成为顶级目录,而不是将其放在fields目录下。自定义的field会覆盖filebeat默认的field。例如添加如下配置:
fields:
level: debug fields_under_root: true
则在Kibana看到的内容如下:
ignore_older:可以指定Filebeat忽略指定时间段以外修改的日志内容,比如2h(两个小时)或者5m(5分钟)。
close_older:如果一个文件在某个时间段内没有发生过更新,则关闭监控的文件handle。默认1h。
force_close_files:Filebeat会在没有到达close_older之前一直保持文件的handle,如果在这个时间窗内删除文件会有问题,所以可以把force_close_files设置为true,只要filebeat检测到文件名字发生变化,就会关掉这个handle。
scan_frequency:Filebeat以多快的频率去prospector指定的目录下面检测文件更新(比如是否有新增文件),如果设置为0s,则Filebeat会尽可能快地感知更新(占用的CPU会变高)。默认是10s。
document_type:设定Elasticsearch输出时的document的type字段,也可以用来给日志进行分类。
harvester_buffer_size:每个harvester监控文件时,使用的buffer的大小。
max_bytes:日志文件中增加一行算一个日志事件,max_bytes限制在一次日志事件中最多上传的字节数,多出的字节会被丢弃。
multiline:适用于日志中每一条日志占据多行的情况,比如各种语言的报错信息调用栈。这个配置的下面包含如下配置:
pattern:多行日志开始的那一行匹配的patternnegate:是否需要对pattern条件转置使用,不翻转设为true,反转设置为falsematch:匹配pattern后,与前面(before)还是后面(after)的内容合并为一条日志max_lines:合并的最多行数(包含匹配pattern的那一行)timeout:到了timeout之后,即使没有匹配一个新的pattern(发生一个新的事件),也把已经匹配的日志事件发送出去1234512345
tail_files:如果设置为true,Filebeat从文件尾开始监控文件新增内容,把新增的每一行文件作为一个事件依次发送,而不是从文件开始处重新发送所有内容。
backoff:Filebeat检测到某个文件到了EOF之后,每次等待多久再去检测文件是否有更新,默认为1s。
max_backoff:Filebeat检测到某个文件到了EOF之后,等待检测文件更新的最大时间,默认是10秒。
backoff_factor:定义到达max_backoff的速度,默认因子是2,到达max_backoff后,变成每次等待max_backoff那么长的时间才backoff一次,直到文件有更新才会重置为backoff。比如:
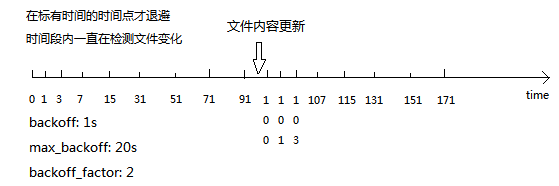
如果设置成1,意味着去使能了退避,每隔backoff那么长的时间退避一次。
spool_size:spooler的大小,spooler中的事件数量超过这个阈值的时候会清空发送出去(不论是否到达超时时间)。
idle_timeout:spooler的超时时间,如果到了超时时间,spooler也会清空发送出去(不论是否到达容量的阈值)。
registry_file:记录filebeat处理日志文件的位置的文件
config_dir:如果要在本配置文件中引入其他位置的配置文件,可以写在这里(需要写完整路径),但是只处理prospector的部分。
publish_async:是否采用异步发送模式(实验功能)。
Filebeat的基本原理其实就是有一群prospector,每个prospector手下管着一批harvester,每个harvester负责监视一个日志文件,把变动的内容由spooler汇总之后交给Logstash或者Elasticsearch。如果想快速搭建一个可以工作的Filebeat,无非有三点:
1.说明要监视哪些文件
filebeat: prospectors: - paths: - "/var/log/lmz.log"1234512345
2.说明收集的日志发给谁
如果直接发送给Elasticsearch,可以设置如下:
output:
如果需要发给Logstash,可以注释掉Elasticsearch的配置,然后设置Logstash如下:
output:
当然,也需要在Logstash的配置中指明要从该端口(5044)监听来自Filebeat的数据:
/etc/logstash/conf.d/beats-input.conf:input { beats { port => 5044 }}123456123456 这里的配置举例是把Filebeat、Logstash、Elasticsearch安装在了一台机器上,实际使用中肯定是分开部署的,需要根据实际情况修改配置文件中的IP地址及端口号。
3.让Elasticsearch知道如何处理每个日志事件。
默认的Elasticsearch需要的index template在安装Filebeat的时候已经提供,路径为/etc/filebeat/filebeat.template.json,可以使用如下命令装载该模板:
$ curl -XPUT 'http://localhost:9200/_template/filebeat?pretty' -d@/etc/filebeat/filebeat.template.json11
当然,也不能忘了,每次修改完Filebeat的配置后,需要重启Filebeat才能让改动的配置生效。
1.下载和安装
https://www.elastic.co/downloads/beats/filebeat11
目前最新版本 1.3.0
这里选择 64-BIT 即方式一 方式一:源码wget https://download.elastic.co/beats/filebeat/filebeat-1.3.0-x86_64.tar.gztar -zxvf filebeat-1.3.0-x86_64.tar.gz1212
方式二:deb
curl -L -O https://download.elastic.co/beats/filebeat/filebeat_1.3.0_amd64.debsudo dpkg -i filebeat_1.3.0_amd64.deb1212
方式三:rpm
curl -L -O https://download.elastic.co/beats/filebeat/filebeat-1.3.0-x86_64.rpmsudo rpm -vi filebeat-1.3.0-x86_64.rpm1212
方式四:MAC
curl -L -O https://download.elastic.co/beats/filebeat/filebeat-1.3.0-darwin.tgztar -xzvf filebeat-1.3.0-darwin.tgz1212
2.配置Filebeat
环境说明:
1)elasticsearch和logstash 在不同的服务器上,只发送数据给logstash 2)监控nginx日志 3)监控支付日志 4)监控订单日志2.1配置
编辑filebeat.yml
vim filebeat.yml11
默认监控日志配置
filebeat: prospectors: - - /var/log/*.log input_type: log 123456123456
按照要求修改为
filebeat: prospectors: - - /www/wwwLog/www.lanmps.com_old/*.log - /www/wwwLog/www.lanmps.com/*.log input_type: log document_type: nginx-access-www.lanmps.com - paths: - /www/wwwRUNTIME/www.lanmps.com/order/*.log input_type: log document_type: order-www.lanmps.com - paths: - /www/wwwRUNTIME/www.lanmps.com/pay/*.log input_type: log document_type: pay-www.lanmps.com #elasticsearch: # hosts: ["localhost:9200"] hosts: ["10.1.5.65:5044"]...其他部分没有改动,不需要修改1234567891011121314151617181920212223242512345678910111213141516171819202122232425
2.2 说明
paths:指定要监控的日志,目前按照Go语言的glob函数处理。没有对配置目录做递归处理,比如配置的如果是:
/var/log/* /*.log11
则只会去/var/log目录的所有子目录中寻找以”.log”结尾的文件,而不会寻找/var/log目录下以”.log”结尾的文件。
2. input_type:指定文件的输入类型log(默认)或者stdin。 3. document_type:设定Elasticsearch输出时的document的type字段,也可以用来给日志进行分类。把 elasticsearch和其下的所有都注释掉(这里Filebeat是新安装的,只注释这2处即可)
output: #elasticsearch: # hosts: ["localhost:9200"]123123
开启 logstash(删除这两行前的#号),并把localhost改为logstash服务器地址
logstash: hosts: ["10.1.5.65:5044"]1212
如果开启logstash了,那么Logstash配置中要设置监听端口 5044:
这个是默认文件位置,如果不存在请自行查找vim /etc/logstash/conf.d/beats-input.conf11
增加端口
input { beats { port => 5044 }}1234512345 3.启动
3.1 测试
-d "Publish"11
如果能看到一堆东西输出,表示正在向elasticsearch或logstash发送日志。
如果是elasticsearch可以浏览: 如果有新内容返回,表示ok 正常后,Ctrl+C结束3.2启动
nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &11
上面会转入后台运行
3.3停止
查找进程 ID
ps -ef |grep filebeat11
KILL他
kill -9 id11
3.X kibana设置
如果使用 kibana 做日志分析,
在kibana里,创建一个索引,注意pattern为:filebeat-*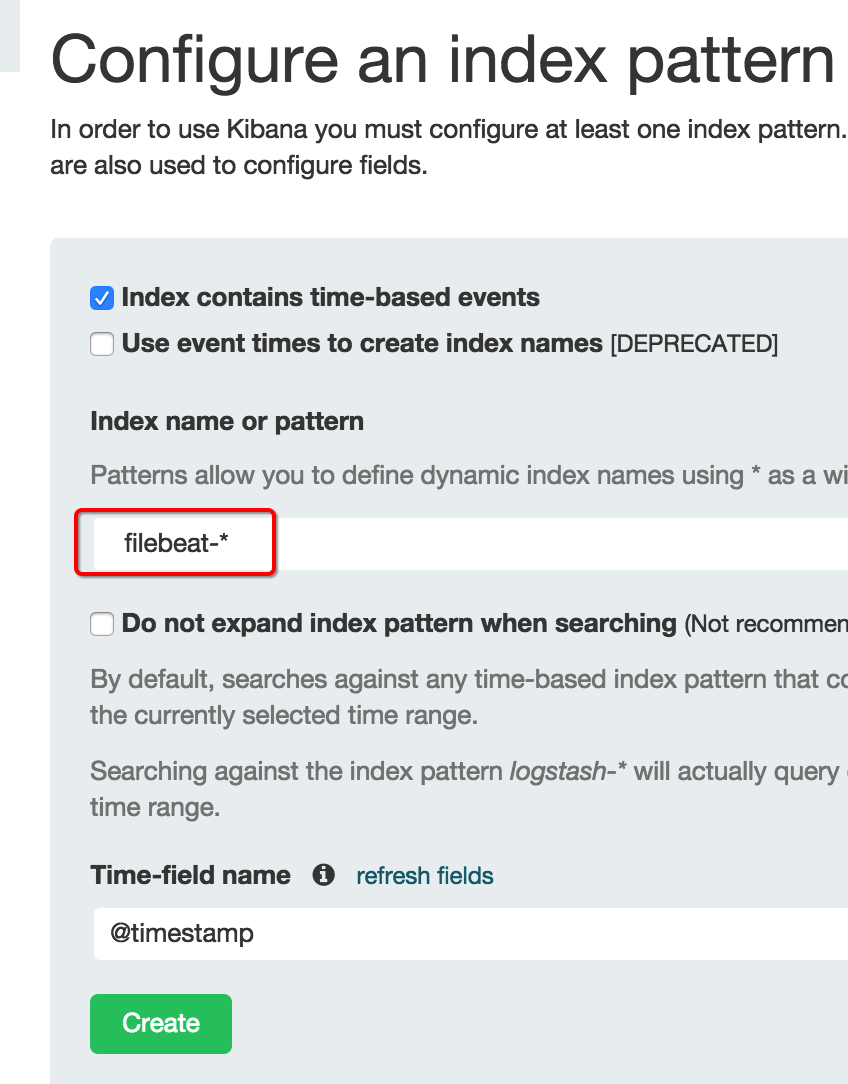
4.高级配置说明
5.其他说明
5.1Elasticsearch知道如何处理每个日志事件
默认的Elasticsearch需要的index template在安装Filebeat的时候已经提供,路径为/etc/filebeat/filebeat.template.json,可以使用如下命令装载该模板:
curl -XPUT 'http://localhost:9200/_template/filebeat?pretty' -d@/etc/filebeat/filebeat.template.json11
如果运行成功则返回如下,表示模板已被接收
{ "acknowledged" : true}123123 每次修改Filebeat配置,重启Filebeat才能生效